
type
Post
status
Published
date
Nov 29, 2023
slug
olap-2
summary
MDX 是OLAP多维数据库的标准查询语言,被许多OLAP产品所支持,包括Microsoft Analysis Services、Oracle Essbase、IBM Cognos,MDX比SQL更适合针对多维数据结构进行查询和分析
tags
OLAP
category
数据分析
icon
password
Language
MDX
概述
- 如果我们请教任何一位熟悉关系型数据库的朋友:“在关系型数据库方面,什么是最核心的技术?”那么答案多半是“SQL 语言”。同样的道理,在 BI 领域,可以认为 MDX 语言是最核心的技术。因为商业智能的一项关键技术是多维数据库,访问多维数据库时使用 SQL 语言是不适用的,我们需要使用另一种语言:MDX。更深一步讨论,MDX 包含两种最主要的用途:SQL 语言可以查询和管理关系型数据库。类似的,MDX 语言可以查询和管理多维数据库。
Mondrian
Pentaho Analysis Services,即 Mondrian(项目代号),是 Pentaho 的多维分析、OLAP 解决方案。Mondrian 就是一个 OLAP 引擎,而且是一个 ROLAP 引擎,ROLAP 指的是使用关系数据库的 OLAP。它本身不管理数据的储存,这是由关系数据库来做的,它通过 JDBC 来访问数据。这样可以大大减少 OLAP 引擎的复杂性,而且可以使用很多种数据库。它实现了这些规范:
- MDX(多维查询语言,相当于数据库的 SQL)
- XMLA(通过 SOAP 使用 OLAP)
- olap4j(Java API 规范,相当于 JDBC 之于关系数据库)Mondrian 采用开源协议是 Eclipse Public License。
基本概念
Cube
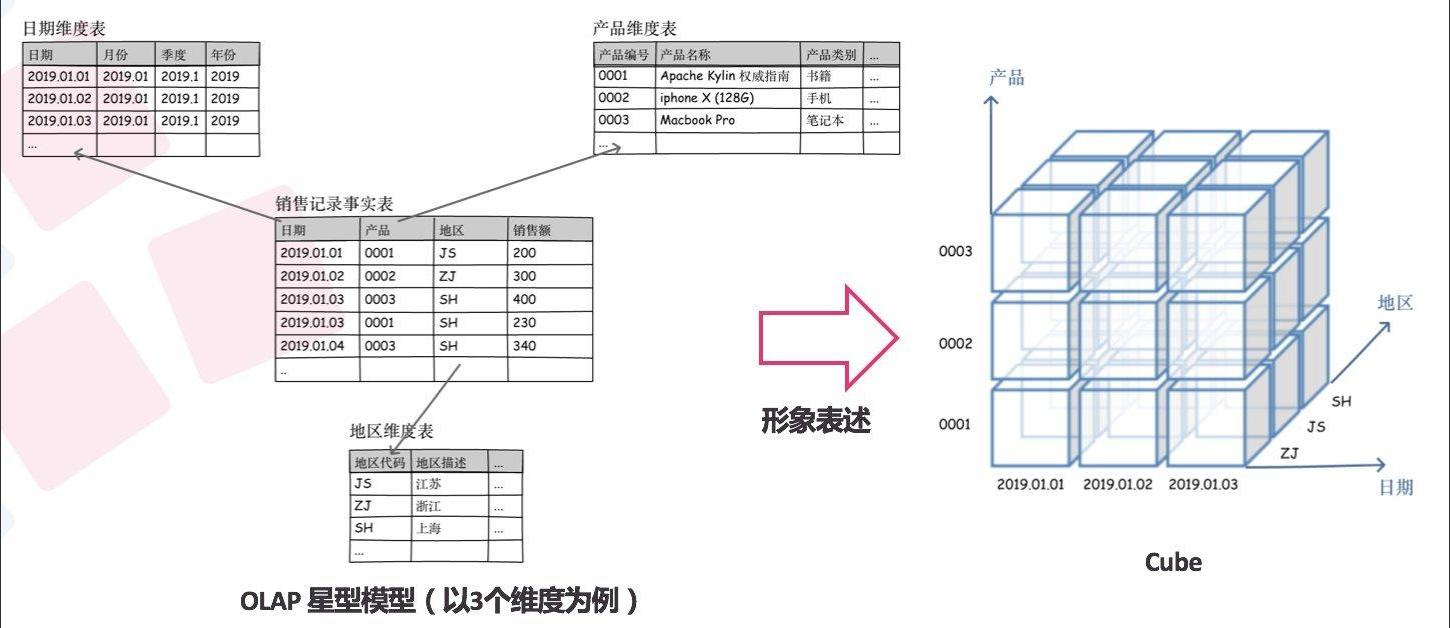
schema
多维数据的事实表、维表、聚集表等存储于数据库中,属于物理模型;而数据立方体、维度、度量这些概念属于逻辑模型。
多维分析引擎必须要理解逻辑模型,并能够映射到物理模型上。多维数据的模式(Schema)就是用来描述这个逻辑模型以及到物理模型的映射的。模式(Schema)是多维数据库的元数据。
MDX
- * **MDX 是这样一种语言,它可以表达在线分析处理(Online Analytical Processing,OLAP)数据库上的选择、计算和一些元数据定义等操作,并赋予用户表现查询结果的能力。但与其他一些 OLAP 语言不同的是,它不是完全用于格式化报表的语言。MDX 查询的结果必须经过某种处理以使它看起来像一个电子制表、图表或者其他的输出形式,这样才能返回到客户程序。这和 SQL 查询关系数据库的工作方式及其相关的应用编程接口(API)的工作方式非常相似。
常见多维分析操作
- 下钻:从高层次向低层次明细数据穿透(全球下钻到东亚)。
- 上卷:和下钻相反,从低层次向高层次汇聚(日本上卷到远东)。
- 切片:将一个或多个维度设置为固定值,观察剩余的维度(将文化的维度限定为宗教)。
- 切块:与切片类似,将维度从一个变成多个(文化的维度限定为宗教、文学、戏曲)。
- 旋转:将数据映射到一张二位表(行列置换)。
查询基础
使用 FoodMart.xml 进行查询
- 查看 1997 年前两个季度加利福尼亚州的销售额与成本

- 显示两个州的前三季的销量,列表示季度,行表示州
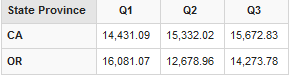
**在查询中,SELECT、FROM 和 WHERE 是表示查询的不同部分的关键字。MDX 查询的结果本身是一个网格,本质上是另一个多维数据集。将查询的多维数据集的维度反映在结果的轴上,该查询通过名称“rows”和“columns”进行引用。在 MDX 术语中,轴(axis)指的是查询结果的边或者维度。采用“轴”这个术语而不是“维度”,使得区分查询的多维数据集的维度与结果的维度变得相对简单。**而且,每个轴都可以是多个多维数据集的维度的组合。(1)关键字 SELECT 后带需要检索内容的子句。(2)关键字 ON 和轴的名称一起使用,以指定数据库的维度显示位置。该示例查询将度量显示为列,将时间段显示为行。(3) MDX 用大括号引用来自某个特定维度或者多个维度的一组元素。这个简单的查询在其两个轴中的每一个上都只有一个维度(度量维度和时间维度)。元素间用逗号,)隔开。元素名称用方括号[]引用,并且不同组成部分之间用点号(.)分隔。(4)在一个 MDX 查询中,可以指定数据库的维度如何在查询结果的轴上布局。上述查询将度量布局成列,将时间段布局成行。不同查询的轴的数量可能不同。前三个轴以“columns”、“"rows”及“pages”命名,以在概念上与打印的报表相匹配(可以用其他方式命名它们。尽管这个简单的查询在结果的每个轴上只显示一个维度,但当多个维度映射到结果的同一个轴上时,每个映射维度的成员构成一个组合,轴上的每个单元槽都会与一个这样的组合相关联。(5) MDX 查询中 FROM 子句指明用于查询数据的多维数据集。这与结构化查询语言(Structured Query Language,SQL)中指定用于查询数据表格的 FROM 子句类似。(6)WHERE 子句指定在列或行(或者其他的轴)上不出现的多维数据集其他维度的成员。如果不对某个维度指定一个成员,MDX 将使用默认值(这里忽略该查询中的括号,直到讨论元组时再作讨论)。WHERE 子句是可选的。一旦数据库确定了查询结果的单元,将会用查询的多维数据集的数据填充它们。MDX 与 SQL 一样使用 SELECT、FROM 及 WHERE 等关键字。但是根据基于 MDX 的教学经验,请注意:假如熟悉 SQL 及其 SELECT、FROM 和 WHERE 的使用方法,那么在学习 MDX 时请尽量忘记 SQL,它们的语义和含义非常不同,尝试将 SQL 概念应用到 MDX 上很可能造成混淆。
轴框架:名称与编号
- * **使用“on columns/rows/pages/etc”语法表明要将成员显示在列、行,或查询结果的其他轴上。轴可以用任何顺序指定。上一个查询如果用下面所示的语句编程,将同样有效并且结果完全相同。
使用轴编号通过声明指定查询中的轴
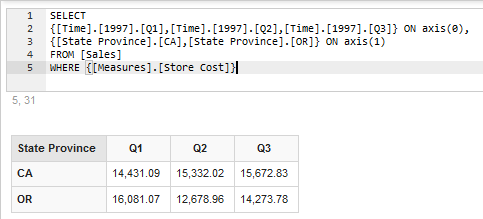
短语 on axis(n)指明哪些成员要在编号为 n 的轴上显示。当前,名称与如下的数字编码是对称的:
0 | Columns |
1 | Rows |
2 | Pages |
3 | Chapters |
4 | Secrions |
也可以混合使用编号,但是不能冲突 比如 ROWS + axis(1)
使用轴 1 的查询必须也使用轴 0,使用轴 2 的查询必须同时使用轴 1 和轴 0。查询中不能跳过前面的轴,否则会出错。下面的程序不能运行,因为它跳过了轴 1:Mondrian Error:Axis numbers specified in a query must be sequentially specified, and cannot contain gaps. Axis 0 (COLUMNS) is missing.
- * **如果把一个 MDX 查询的结果看作是一个超多维数据集(或者子多维数据集),并且把每个轴看作该超多维数据集的一个维度,那么就会明白跳过一个轴会出问题。
大小写敏感与布局
MDX 既不是大小写敏感的,也不是一行一行处理的。例如,下面两个程序片断同样有效:
SELECT {[Time].[1997].[Q1],[Time].[1997].[Q2],[Time].[1997].[Q3]} ON COLUMNS,...SELECT {[Time].[1997].[Q1],[Time].[1997].[Q2],[Time].[1997].[Q3]} ON columns,...可以随心所欲地混用字母大小写,对于语言的关键字,大小写无所谓。
至于名称,对于 MDX 提供者而言,大写可能有影响,也可能没有。
对于 Analysis Services 或 Essbase,大小写没有影响,尽管后面会碰到某些 Essbase 关心大小写的情况。
在哪里放置空格及行在哪里结束,同样没有影响,可以用下面的代码重写前面的程序片断:
构造简单的 MDX
先建立一个小的词汇表,然后查看一些最简单且最常用的操作符和函数。
这里将对它们做个简单的介绍并描述通常应如何使用
这里将讨论的函数和操作符包括:
逗号(,)和冒号(:)
在讨论这些函数和操作符时,将使用术语“集(set)”。集是 MDX 中相当重要的概念,
在每个维度的每个级别上,该级别的成员按照特殊的顺序排列(通常按照成员键或者名称排列)。当这个排列顺序有某种意义时,将来自同一级别的成员作为端点,并用冒号隔开,这表示“这两个成员及其中间的所有成员”这样按照指定的顺序排列的成员构成一个“集”。
- 查询 1997 年 1 月到 6 月进口啤酒到体育月刊销售额
- * **当数据库定义的顺序和现实中的顺序(如时间顺序)相关时,一般采用上面的方式建立集。冒号用同一级别的两个成员作为端点。在冒号两边可以是相同的成员,表示集中只有一个成员
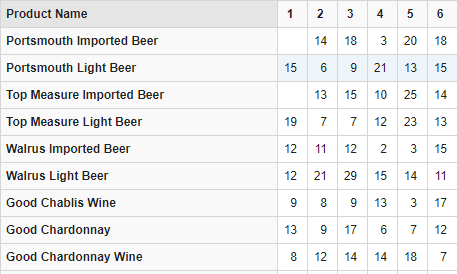
- * **在给集中添加子集时,可以在该集中任何地方使用逗号操作符。例如,下面的语句产生包含 1997 年前三个月和后三个月的集:
- * **而下面的语句产生包含 1997 年及其前三个月的集:
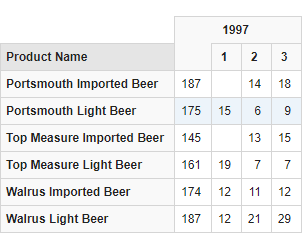
.Members
- * **无论用于检索,还是作为更复杂的操作的基础,获得一个维度、层次结构或者级别的成员的集是非常普遍的操作。
- * **维度、层次结构或者级别放置在.Members 操作符的左边,可以返回由该元数据范围内所有成员构成的集。
例如,[CustomcrJ.Members 产生包含所有顾客的集,而[ProductJ.[Product Category].Members 返回 Product,维度中 Product Category 级别的所有成员。
例如,查询:
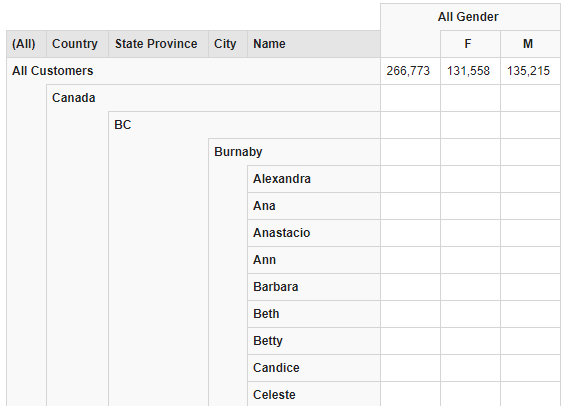
- * **逐列显示 Gender 维度的所有成员,并且逐行显示 Customers 维度的所有成员。当客户端使用.Members(或者其他的元数据函数,这些函数返回与某个元数据要素相关的成员集)
.Children
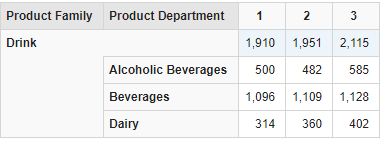
- * **另外一种非常常用的查询是获得一个成员的子成员。这么做的目的可能是执行一个向下钻取操作,或者为了方便地获得基于一个共同父成员的范围内的成员。MDX 提供.Children 函数来完成这个操作。
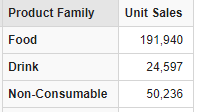
下面的查询将选择[Product].[ Drink]成员和它的子成员,并在报表的各行上显示,如图
.Descendants
- * **为了得到直接子代之下的后代成员,或者更普遍的,为了搜索本层次结构之下的成员,可以使用 Descendants()。
语法
Descendants (menber [, [level] [,flag]] )Descendants()返回 member 之下与 level 或者代次相关的成员,并且对于可选参数 flag,有很多选项。Flag 的可选值有:
- SELF
- BEFORE
- AFTER
- SELF_AND_BEFORE
- SELF_AND_AFTER
- SELF_BEFORE_AFRER
- LEAVES
- * SELF 仅仅指 member 以下 level 级别上的成员,这是最常用的选项。例如,下面的语句选择 1997 年的月份**

- * **因为 SELF 很常用,所以如果忽略 flag 参数,那么默认使用 SELF。例如,即使没有在查询中显式地包含 SELF,Descendants ([Time].[Year],[Time].[Month])也会返回 2005 年的月份列表
- * **其他的包含 SELF 的标志指的是参考级别附近的级别。SELF_AND_BEFORE 意味着返回 member 所在级别以及 level 级别之间的所有成员,也就是包含 member 在内、从 level 级别到 member 级别的所有成员。例如,下面的语句选择 1997 年及其所有季度和该年的所有月份,

SELF_AND_AFTER 意味着返回从参考级别 level 到叶级别之间的所有成员。
SELF_BEFORE_AFTER 意味着从给定的成员 member 开始到下面叶级别之间的整个子树。
注意,这与 Descendants ([Time].[1997])效果相同,因为不使用标志 flag 和级别 level 参数意味着取回所有后代成员。也要注意到可以使用数字而不是级别的引用,来访问特定级别的后代成员或者距离给定成员一定深度的后代成员。
去除查询结果中的空切片
在一个多维空间中,数据稀疏现象很常见。
例如,不是所有的产品都会在任何商店、任何时间段卖给每一位顾客,所以对特定的产品集、时间段和顾客的查询,可能会返回一些在一个或者多个轴上完全为空的切片。
应该非常确定,没有哪个零售商会 12 月在夏威夷卖雪铲,但是它们在芝加哥却很难有库存。
某位用户希望看到空的切片,因为空切片可以告诉他或她自己在某处缺乏行动;但是该用户也可能对这些空切片不感兴趣,并想将其从报表中移除。
- *去除空切片需要做的仅仅就是在待移除空切片的轴前面加上 **NON EMPTY 关键字。
在本例中,NON EMPTY 的位置是在 ON COLUMNS 后面的逗号之后,在标识要查询的产品的左大括号“{”之前。先计算查询,在各列所有的数据都得到之后,最后返回至少在一列上有数据的行。
NON EMPTY 可以用在任何轴、维度和元组上。可以将上述查询的行列交换如下:
还有其他函数可以用来从查询结果中去除带有空数据的成员,但是 NON EMPTY 是最适合做这个操作的。
注释
为了方便编写程序文档,MDX 中可以使用 3 种注释语法,这无疑可以适合于很多编程风格(就像其他的编程语言一样,为了调试方便,在 MDX 中也可以将部分代码注释掉),
第一种风格
第二种风格
第三种风格
MDX 数据模型 : 元组和集
元组
一个元组是来自一个或多个维度的成员的组合,它本质上是个多维成员。
单个成员是个简单的元组(例如,[Time].[Jun, 2005)。
当一个元组有多个维度时,对于每个维度,它只能有一个成员来自其中。
为了组成一个多维的元组,必须使用括号将成员括起来,例如:
([Product].[Food],[Time].[Year].[1997])一个元组可以代表多维数据集的一个切片,这样多维数据集就被元组中的每个成员分割。一个元组也可以是 MDX 中独立操作的数据对象。
使用上述语法可以直接在查询中包含元组。
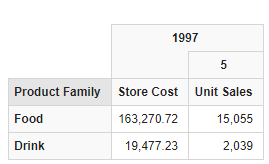
从返回的结果可以看出,本例采用的时间和度量的组合不是很对称。
但这一点也说明可以随心所欲地控制从查询返回什么样的成员和单元的组合。
也可以将一个成员放入括号,但是如果元组仅由那一个成员构成,则不一定要那样做。但是下面的元组无效,因为它有两个时间维度。
([Product].[Food],[Time].[Month].[5],[Time].[Month].[8])也不能构成空的元组。()是无效的元组
除了通过在代码中显式地组成元组外,还有很多函数返回元组。
元组的“维度范围”指的是组成该元组的成员的维度的集合。
对于元组的维度范围而言,维度在元组中出现的顺序很重要。
所有的维度都可以成为元组的一部分,包括度量维度。
可以通过括号()组成元组,但是不能用元组构成元组。也就是说,可以按如下方式构建一个元组:
([Product].[Food],[Time].[Month].[5],[Time].[Month].[8])
- *但是不可以 : **
([Product].[Food],
- * **(
- * **[Time].[Month].[5],
- * **[Time].[Month].[8]
- * **)
)
在计算和查询中,MDX 通过元组来区分单元。
从概念上讲,每个单元由其对应的元组确定,而该元组的成员来自多维数据集的与单元对应的维度(这与电子制表有几分像,其中表 1,列 B,行 22 标识一个单元。)
在一个查询中,成员的有些维度显示在行上,有些显示在列上,有些则显示在页上,其他的放在查询切片器中。
但是,两个或更多的元组的交集可以构成另一个元组,所以把这些元组全部组合在一起最终就会得到一个单元。
元组([Product].[Leather Jackets],[Time].[June-2005],[Store].[Fifth Avenue NYC],[Mcasures].[DollarSales])可能完全定义了一个值为 13000 美元的单元。
尽管一个元组就是成员的组合,但当该元组在由数字或字符串构成的表达式中应用时,它默认的作用是注明该元组对应的单元的值的来源。
这一点对于理解 MDX 某些函数的功能非常重要。
集
集是元组的有序集合。一个集可能有不止一个元组,也可能只有一个元组,或者是空的。
与数学的集合不同,MDX 集可能多次包含同样的元组,而排序在 MDX 集中非常重要。
尽管集称为“聚集”或者“序列”可能较好,但是眼下坚持使用“集”。
根据集使用的上下文,它要么是指元组集合,要么是指元组指定的单元的值。
从语法上讲,有很多方法指定一个集。
但最普遍的方法可能就是用列举构成集的元组。下面的查询使用两个集,其中行的集是一维的,列的集是二维的。
任何时候显式列举元组,都要用大括号括起来。
一些 MDX 操作符和函数也返回集。
如果集不是由多个元组构成,则使用它们的表达式不需要用大括号括起来,但是因为编程风格的原因,通常还是会用大括号将集表达式括起来。
虽然单个成员默认是一个一维度的元组,但是一个元组并不等价于只有一个元组的集。就标准 MDX 而言,下面的两个示例差别较大:
下面的查询在所有的 MDX 查询中都有效
类似地,碰巧只包含一个元组的集仍被看作一个集。
所以,即使能确定一个集只包含一个元组,但要在需要使用元组的上下文中(例如,在 WHERE 子句中)使用它,还是必须调用 MDX 函数从该集返回元组。
集也可以是空的,既可能因为显式的定义(例如,0),也可能是由于某些原因函数返回了一个空集。
集中的每个元组都有同样的维度范围(即元组的维度及其在元组中的顺序)。下面的语句将会发生错误,因为维度的顺序改变了:
但是,为了满足各种需要,不同的集可以拥有不同的维度和维度顺序。空集没有维度范围。除了通过编码显式地创建集,还有很多函数返回集。
查询
MDX 查询的结果就是从查询的多维数据集转化而来的另一个多维数据集。
这与标准的 SQL 查询结果类似,它本质上是另一张表。
结果多维数据集可以有一个、两个、三个、四个或者更多的轴。
从技术上讲,一个查询也可能有 0 个轴,但是它仍然会返回一个单元的值。
一个结果轴上的每个元组本质上是结果多维数据集的一个成员。
正如前面所描述的,查询结果的每个轴由许多元组构成,每个元组都有一个或多个维度。
当多维元组在查询的轴上结束时,维度在元组中的顺序将影响轴上的嵌套顺序。
列表中第一个维度成为最外面的维度,第二个成为次外面,以次类推,最后一个维度在最里面。例如,假设下面的集在结果的“行”轴上显示:
在这个示例中,通过用于 OLAP 的 OLE DB 或者 ADO 返回到客户端的数据的预期结果。
零轴查询
SELECT FROM [Sales]和
因为上面两个查询都没有把成员分配到任何(无限制器)轴上,所以认为结果有零轴,并且按照惯例,结果将只是无标号的单元,或者是没有不同的行标题或列标题的单元。
在当前支持 MDX 的所有 API 中,限制器的信息作为查询结果的一部分返回。而是否把结果当作零轴,取决于在切片器信息随单元一起返回时,是否忽略其中传达的维度信息。.
只有轴的查询
注意,所有的 MDX 查询都返回单元。
但是,如果真正感兴趣的结果不是单元的数据,而是与单元数据或者成员属性值相关的成员,那么很多实用的查询会询问“什么样的成员属于这个集”。
一个这种形式的查询如“显示占我们的财政收入百分比前十名的顾客”,也将隐式地要求单元值集(但是,由于内部的最优化机制,上面的查询将得不到那些单元值)。
这与 SQL 形成鲜明对比,SQL 只返回查询的列。
更多方法
CrossJoin
在许多情况下,如果想要获取两个不同的集的成员(或元组)的交叉组合(即,指定它所有可能的组合),CrossJoin()函数是以这种方式组合两个集的最直接方法。语法如下:
CrossJoin (set1, set2)例如,如果想要在列上显示 1997 年前两个季度的门店销售额和产品销售件数,使用下面的表达式就可以产生这个集;
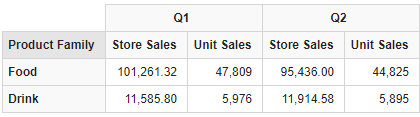
CrossJoin()只采用两个集作为输入。如果想输入 3 个或者更多的集,诸如 Time.Scenario 及 Product,可以通过嵌套调用 CrossJoin()达到目的,如下所示:
注意,这两个调用都产生同样的集,它的维度范围按顺序是 Time、Scenario 及 Product.而读者可能偏爱某个函数,当这个集较大时,还可能想弄清在自己的 MDX 软件内这些函数的性能差异。
CrossJoin()属于标准 MDX。icrosoft Analysis Services 利用(星号)将上述功能扩展表示成“集的乘法”,即:*
{[Time].Members} * {[Customers].Members} * {[Product].Members}这种表示法执行了与 CrossJoin()相同的操作,而且如果不考虑简便与否的话,这种表示法可能更加容易读写。
CrossJoin)的一个常见用法是把某个维度的单个成员与另一个维度的若干成员组合起来,例如,通过把一个特殊的度量与其他维度的许多元组组合在一起,来创建一个集。
当在某个计算度量的公式中涉及到统计另一个度量的非空单元的数量时,就需要这个结构。不能使用范围操作符构造多个维度的元组,尽管这个想法看起来可行。
- *例如,要表达“1 到 10 号商店的牙膏”这个范围概念,有可能想编写下面的语句 ; **
但相反,实际需要使用 CrossJoin()(或者*形式),如下所示:
在前面有些 CrossJoin()示例中,在语句的表达方式上,没有使用大括号将集括起来,因为那里没必要用大括号。但是,既然函数需要一个集作为参数,那么这里用大括号将单个成员[Toothpaste]括起来,以将元组转化成一个集,确实要好些。
================= 未完待续。。。。
FoodMart 立方体分析
维度
Customers
Product
指标
- Unit Sales : 单位产品销售额
- Store Cost : 存储成本
- Store Sales : 店销售
- Sales Count : 销售统计
- Customer Count : 客户数
- Promotion Sales : 促销额
- Profit : 利润
- Gewinn-Wachstum : 盈利增长
- 作者:何以问
- 链接:https://heyiwen.com/article/olap-2
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。

.jpg?table=collection&id=e7f4915d-967b-426f-8bcd-25b05e1a8ebb&t=e7f4915d-967b-426f-8bcd-25b05e1a8ebb&width=1080&cache=v2)





