
type
Post
status
Published
date
Apr 24, 2025
slug
agent-1
summary
tags
Agent
category
AIGC
icon
password
Language
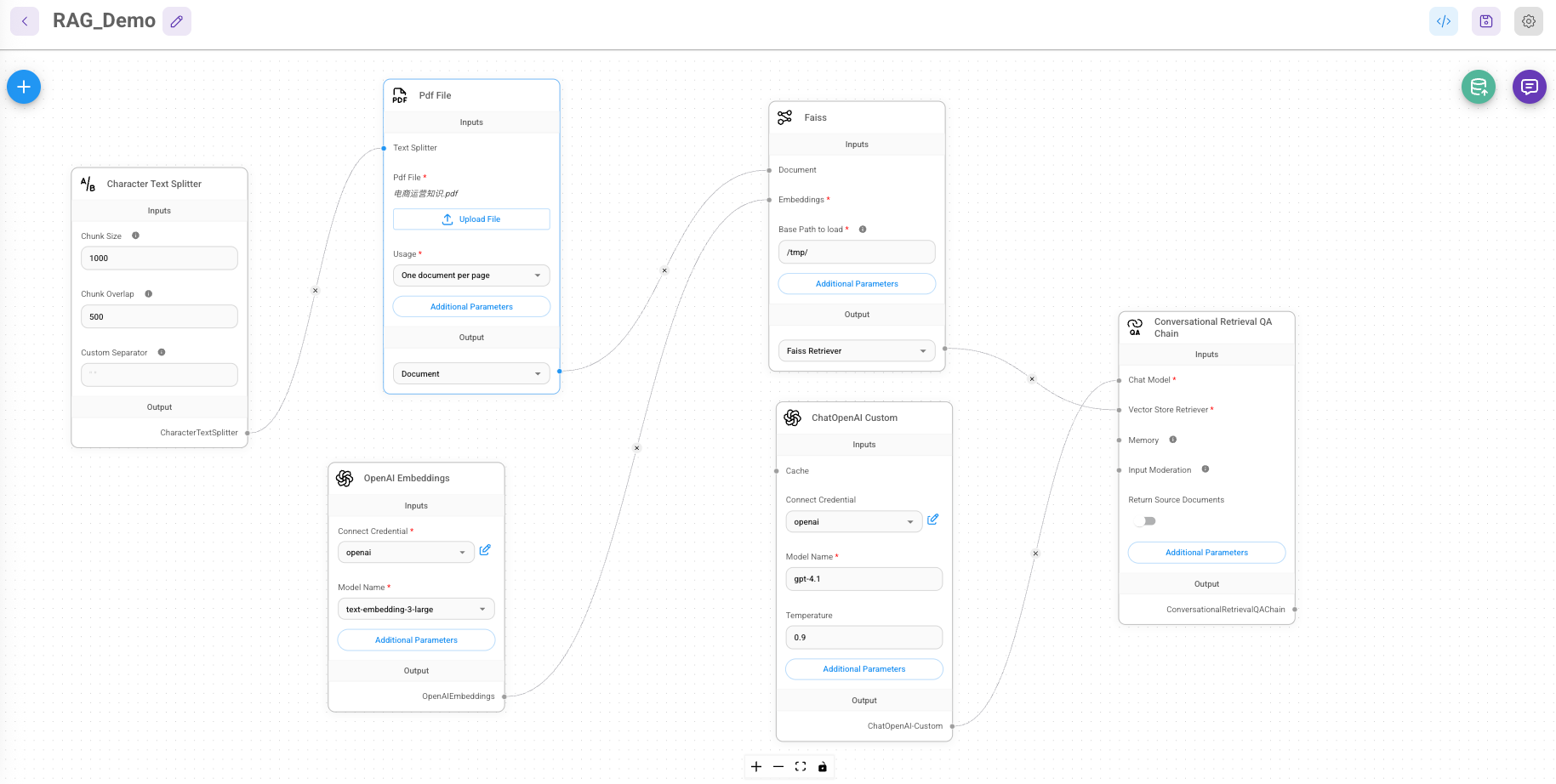
使用 Flowise 构建基于 RAG 的问答系统
本文将详细介绍如何使用 Flowise 构建一个基于 RAG(Retrieval-Augmented Generation) 的问答系统。我们将从文档加载到最终对话的完整流程进行讲解,帮助您快速上手并理解每个步骤的关键点。
1. 加载文档
在构建 RAG 系统的第一步,我们需要加载目标文档。Flowise 提供了多种组件来支持不同格式的文件加载。在这里,我们选择使用 Pdf File 组件来加载 PDF 文件。
通过该组件,您可以轻松上传和解析 PDF 文件,为后续的文本处理做好准备。
2. 文本分割
为了更好地处理和检索文档内容,我们需要对加载的文本进行分割。Flowise 提供了 Character Text Splitter 组件,用于将长文本切割成更小的片段。

以下是该组件的主要参数:
- Chunk Size :每个片段的字符数,默认值为 1000。
- Chunk Overlap :相邻片段之间的重叠字符数,默认值为 200。注意,这个值不能大于或等于 Chunk Size。
- Custom Separator :自定义分隔符,用于确定分割位置,会覆盖默认分隔符。
合理设置这些参数可以确保分割后的文本片段既独立又连贯,为后续的嵌入和检索打下基础。
3. 嵌入(Embedding)
嵌入是 RAG 系统的核心步骤之一,它将文本数据映射到高维向量空间,以便进行高效的相似性检索。在 Flowise 中,我们可以选择多种嵌入模型。本文中,我们使用 OpenAI 的 text-embedding-3-large 模型。
该模型能够生成高质量的文本向量,为后续的向量存储和检索提供强有力的支持。
4. 向量存储
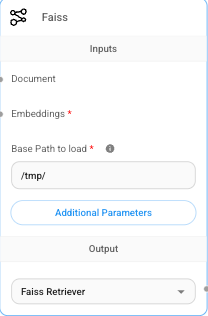
Faiss 向量数据库
Flowise 集成了多种向量存储数据库,其中 Faiss 是由 Facebook(现 Meta)开源的高性能向量数据库。它非常适合大规模向量检索任务。
在 Flowise 中,Faiss 组件的必填项包括:
- Embeddings :需要连接到前面配置的嵌入模型组件。
- Base Path to Load :指定向量数据的存储路径。
通过将 OpenAI Embeddings 和 Pdf File 组件连接到 Faiss 组件,我们可以将生成的向量数据持久化存储。
5. 检索与问答
Conversational Retrieval QA Chain
这是 RAG 系统的核心组件,用于执行带有检索功能的问答任务。通过该组件,我们可以实现基于文档知识的智能问答。
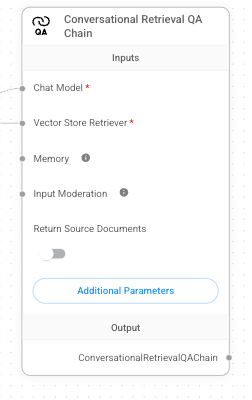
它的关键参数包括:
- Chat Model :选择一个大语言模型(如 GPT-4 或其他支持的模型)。
- Vector Store Retrieval :连接到前面配置的 Faiss 组件。
完成配置后,保存设置即可进入下一步。
6. 解析与更新向量存储
在保存配置后,右上角的对话按钮旁边会出现一个图标,表示系统已准备好进行解析和更新。
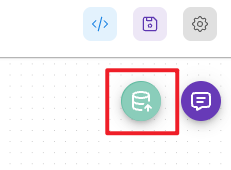
点击 Upsert Vector Store 按钮,等待系统完成向量存储的更新操作。
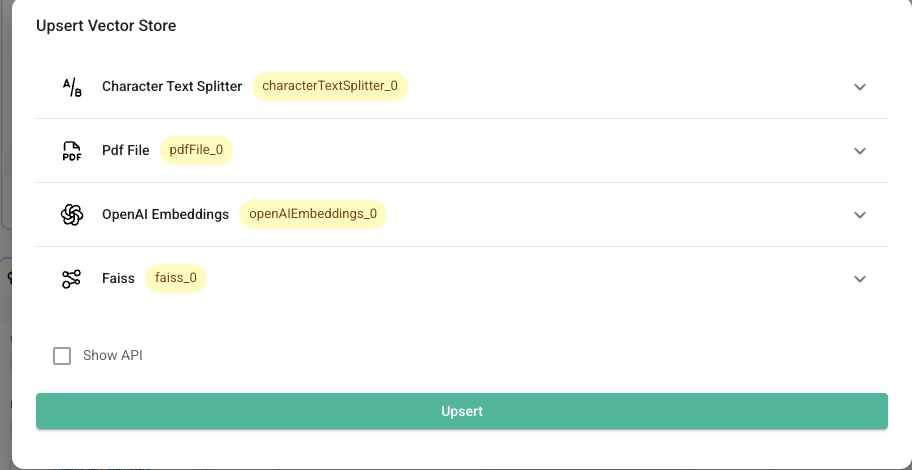
更新完成后,系统即可开始基于文档知识的对话交互。
7. 对话效果展示
对话界面
在完成上述步骤后,您可以与系统进行对话,体验基于文档知识的问答功能。

文档知识提取
系统能够准确地从文档中提取相关信息,回答您的问题。
总结
通过 Flowise 构建基于 RAG 的问答系统,我们可以高效地实现从文档加载到智能问答的全流程。以下是关键步骤的总结:
- 加载文档 :使用 Pdf File 组件加载目标文档。
- 文本分割 :通过 Character Text Splitter 将文本切割为适合处理的小片段。
- 嵌入 :利用 OpenAI 的 text-embedding-3-large 模型生成高质量的文本向量。
- 向量存储 :借助 Faiss 数据库存储和管理向量数据。
- 检索与问答 :通过 Conversational Retrieval QA Chain 实现基于文档知识的智能问答。
- 解析与更新 :完成向量存储的更新,确保系统能够实时响应。
- 对话体验 :与系统交互,验证问答效果。
希望本文能帮助您快速掌握 Flowise 的使用方法,并成功构建自己的 RAG 系统!如果您有任何问题或建议,欢迎在评论区留言交流。
- 作者:何以问
- 链接:https://heyiwen.com/article/agent-1
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。




.jpg?table=collection&id=e7f4915d-967b-426f-8bcd-25b05e1a8ebb&t=e7f4915d-967b-426f-8bcd-25b05e1a8ebb&width=1080&cache=v2)


